I will avoid an introduction and get straight to it. I’ll assume that you know what Turing-complete means, that you are familiar with transformers, and that you care about the question: Are transformers Turing-complete? (I may later write about what that question means and why it is important.)
Several papers claim that transformers are Turing-complete and therefore capable of computing any computable function. But I believe these claims are all misleading. Some make conceptual errors and are simply incorrect in their claims of Turing-completeness for their models. Others have modified the essential properties of transformers to achieve universal computation, presenting models that only resemble transformers superficially. As of October 2024,the deep learning model widely known as a ‘transformer’ (despite its success in commercial large language models) has not been shown to be Turing-complete (barring add-ons and modifications to its essential properties).
Imagine a conversation with one of these newly released AI chatbots. You ask it it to solve a tricky math problem. It responds with “That seems kind of hard. Give me some time to think.”. After a few minutes it comes back with “I haven’t solve it yet. And I am not sure I can. Would you like me to continue working on it?”. Another few minutes pass and then it comes back with “Aha! I figured it out!” and it proceeds to explain a neat and creative solution.
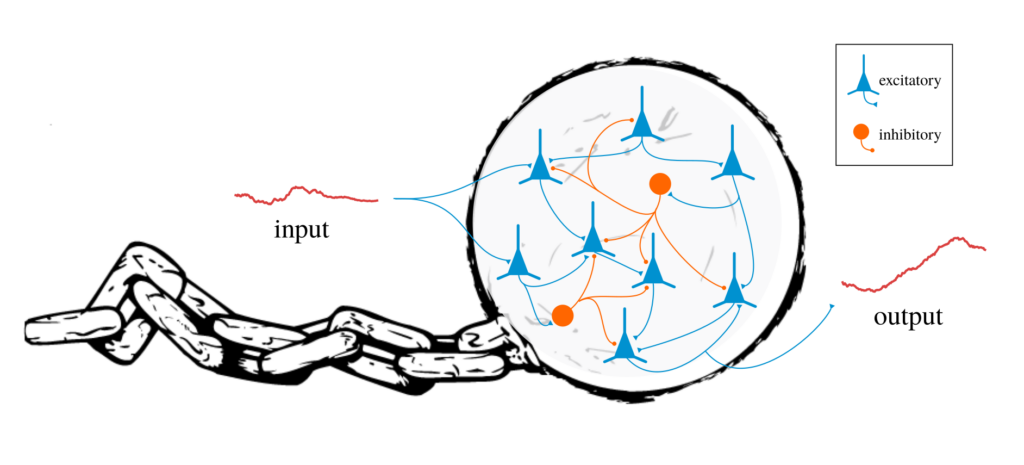
This scenario can never occur with PaLM, BARD, GPT-4, or any of the other transformer-based large language models that are thought to be on the path to general intelligence. In all of these models, each word in the machine’s response is produced in a fixed amount of time. The model cannot go away and “think” for a while. This is one of the reasons why I believe a solely transformer-based model can never be “intelligent”. (If you disagree with my characterization of transformers here, see section 4 and also this post).
Summary: I argue here, that intelligence requires the ability to explore “trains of thought” that are potentially never-ending. One cannot know a priori if a certain train of thought will lead to a solution or if it is futile. The only way to find out is to actually explore. And this type of exploration comes with the risk of never knowing if you are on the path to a solution or if your current path will go on forever. Intelligence involves problem-solving, and problem-solving requires arbitrary amounts of time. If a computer program is bound to finish quickly by virtue of its architecture, it cannot possibly be capable of general problem-solving.
In the summary paragraph above, I appealed to a number of intuitive notions (e.g. “train of thought”, or “exploration”, or “problem-solving”). In order to make my argument rigorous, I have to first introduce a few concepts rooted in classical theory of computation. In section 1, I will introduce three types of computer programs. In section 2, I describe what an unintelligent problem-solver can look like. In section 3, I describe what is needed to make the unintelligent problem-solver intelligent. In section 4, I explain why transformers can never be general problem-solvers. In section 5, I briefly discuss what I think needs to be done to address this problem.
This blog post is written as a dialogue between two imaginary characters, one of them representing myself (H) and the other a stubborn straw man (S). It is broken into four parts: the dogma, the insight, the decoy, and the clues. If you do not feel like reading the whole thing, you can skip to part 4; it contains a summary of the other parts.
If you believe in the following, I am going to try to change your mind:
“Turing machines aren’t realistic. They need infinite memory so they can’t be implemented. Any real computing device is limited in its memory capacity and, therefore, equivalent to a finite state machine.”
Cartoon of a Turing Machine by Tom Dunne, 2002
This is a fairly commonly held view. I used to believe in it myself, but had always found it deeply unsatisfying. After all, modern-day computers have limited memory capacity but closely resemble Turing machines. And Turing’s abstract formulation arguably led to the digital revolution of the 20th century. How, then, can the Turing machine be a physically irrelevant mathematical abstraction? If all of our computers and devices are of the weaker class of computers, namely, finite state machines, why do they have to look so much like Turing machines?
It is important to clarify this, especially for neuroscience and computational biology. If we think of Turing-equivalence as this abstract level of computation that is impossible to physically achieve, then we block out classical insights from the theory of computation and cannot even begin to ask the right questions. (I recently wrote a manuscript asking the question “where is life’s Turing-equivalent computer?” and showed that a set of plausible molecular operations on RNA molecules is sufficient to achieve Turing-equivalent computation in biology).
It took a good amount of reading and thinking to finally understand the meaning of Turing-equivalence. I will explain what I believe to be the only consistent way of looking at this issue. Here is the short version:
When we say Turing machines require “unbounded memory”, what we mean is that memory cannot be bounded by the systems descriptor, not that it cannot be bounded by other things such as the laws of physics or resource constraints. Turing-equivalence only requires a system in which memory usage grows, not one in which memory is infinite.
Below I explain precisely what all that means. I will try to convince you that this is the only consistent way of looking at this and that Turing, himself, shared this perspective.