I will avoid an introduction and get straight to it. I’ll assume that you know what Turing-complete means, that you are familiar with transformers, and that you care about the question: Are transformers Turing-complete? (I may later write about what that question means and why it is important.)
Several papers claim that transformers are Turing-complete and therefore capable of computing any computable function. But I believe these claims are all misleading. Some make conceptual errors and are simply incorrect in their claims of Turing-completeness for their models. Others have modified the essential properties of transformers to achieve universal computation, presenting models that only resemble transformers superficially. As of October 2024,the deep learning model widely known as a ‘transformer’ (despite its success in commercial large language models) has not been shown to be Turing-complete (barring add-ons and modifications to its essential properties).
Every so often a new neural network makes headlines for solving a computation problem. It is sometimes hard for me to judge how impressive these achievements are without diving into the details of the models. But my criteria are always the same and it should be easy for those who are familiar with their models to evaluate based on these criteria. For this purpose I have made a flowchart for how impressed I would be at a neural network. If you know of a new neural net that reaches “wow” please let me know about it, and if it reaches “mind-blown” you have permission to wake me up in the middle of the night – since I know no examples.
This blog post is written as a dialogue between two imaginary characters, one of them representing myself (H) and the other a stubborn straw man (S). It is broken into four parts: the dogma, the insight, the decoy, and the clues. If you do not feel like reading the whole thing, you can skip to part 4; it contains a summary of the other parts.
If you believe in the following, I am going to try to change your mind:
“Turing machines aren’t realistic. They need infinite memory so they can’t be implemented. Any real computing device is limited in its memory capacity and, therefore, equivalent to a finite state machine.”
Cartoon of a Turing Machine by Tom Dunne, 2002
This is a fairly commonly held view. I used to believe in it myself, but had always found it deeply unsatisfying. After all, modern-day computers have limited memory capacity but closely resemble Turing machines. And Turing’s abstract formulation arguably led to the digital revolution of the 20th century. How, then, can the Turing machine be a physically irrelevant mathematical abstraction? If all of our computers and devices are of the weaker class of computers, namely, finite state machines, why do they have to look so much like Turing machines?
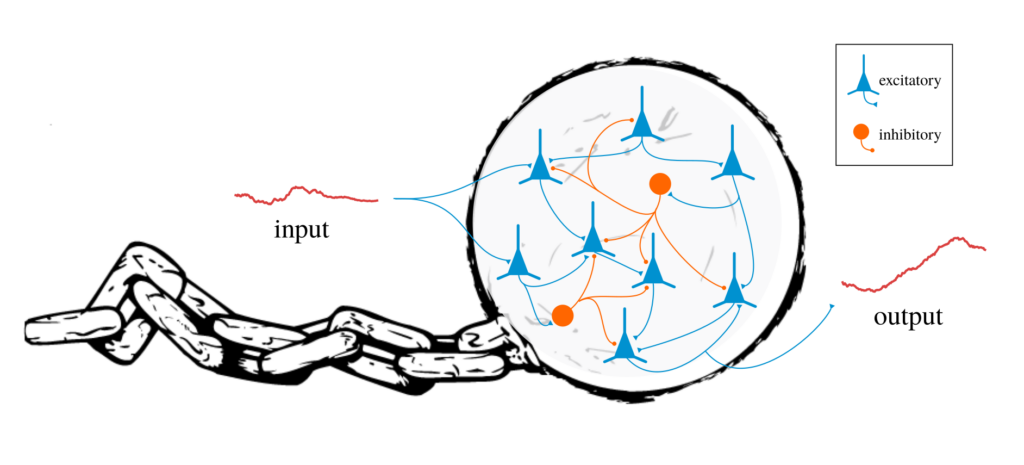
It is important to clarify this, especially for neuroscience and computational biology. If we think of Turing-equivalence as this abstract level of computation that is impossible to physically achieve, then we block out classical insights from the theory of computation and cannot even begin to ask the right questions. (I recently wrote a manuscript asking the question “where is life’s Turing-equivalent computer?” and showed that a set of plausible molecular operations on RNA molecules is sufficient to achieve Turing-equivalent computation in biology).
It took a good amount of reading and thinking to finally understand the meaning of Turing-equivalence. I will explain what I believe to be the only consistent way of looking at this issue. Here is the short version:
When we say Turing machines require “unbounded memory”, what we mean is that memory cannot be bounded by the systems descriptor, not that it cannot be bounded by other things such as the laws of physics or resource constraints. Turing-equivalence only requires a system in which memory usage grows, not one in which memory is infinite.
Below I explain precisely what all that means. I will try to convince you that this is the only consistent way of looking at this and that Turing, himself, shared this perspective.