
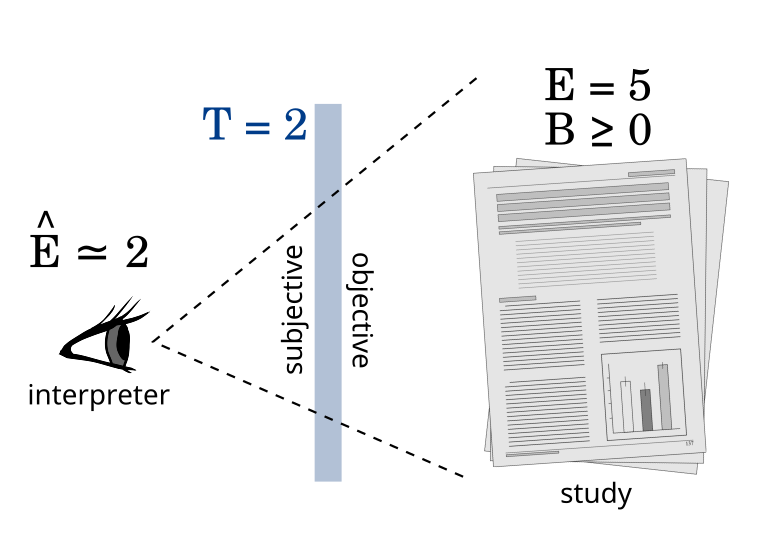
In part 1, we defined evidence and showed that evidence across independent studies can be aggregated by addition; if Alice’s results provide 2 units of evidence and Bob’s results provide 3 units of evidence then we have a total of 5 units of evidence. The problem with this is that it doesn’t account for our intuition that single experiments cannot be trusted too much until they are replicated. 10 congruent studies each reporting 2 units of evidence should prevail over one conflicting study showing -20 units of evidence.
Let’s try to model this by assuming that every experiment has a chance of being flawed due to some mistake or systematic error. Each study can have its own probability of failure, in which case the results of that experiment should not be used at all. This is our first assumption: that any result is either completely valid or completely invalid. It is a simplification but a useful one.
We define trust (T) in a particular study as the logarithm of the odds ratio for the being valid versus being invalid. In formal terms:
Continue reading “Quantifying Evidence (2): Evidence Is Limited By How Much a Study Can Be Trusted”