
In part 1, we defined evidence and showed that evidence across independent studies can be aggregated by addition; if Alice’s results provide 2 units of evidence and Bob’s results provide 3 units of evidence then we have a total of 5 units of evidence. The problem with this is that it doesn’t account for our intuition that single experiments cannot be trusted too much until they are replicated. 10 congruent studies each reporting 2 units of evidence should prevail over one conflicting study showing -20 units of evidence.
Let’s try to model this by assuming that every experiment has a chance of being flawed due to some mistake or systematic error. Each study can have its own probability of failure, in which case the results of that experiment should not be used at all. This is our first assumption: that any result is either completely valid or completely invalid. It is a simplification but a useful one.
We define trust (T) in a particular study as the logarithm of the odds ratio for the being valid versus being invalid. In formal terms:
![\[ T = (\text{subjective trust in a particular result}) = \log_{10}\left(\dfrac{Pr(\text{valid})}{Pr(\text{invalid})}\right) = \log_{10}\left(\dfrac{Pr(V)}{Pr(\overline{V})}\right) \]](https://lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-b949a29bb7dd06e14a737477fa9cd508_l3.png "Rendered by QuickLaTeX.com")
A trust T=2 corresponds to a belief that the odds the outcome being flawed is 1 to 100. T=3 corresponds to an odds of 1 to 1000. In my view, 1<T<3 is reasonable for the typical study. But trust is something subjective that cannot be objectively calculated. Much like priors, it depends on the person sitting outside of the study interpreting its results.
Take a study with data  that reports evidence
that reports evidence  . That study can either be valid or invalid (represented by
. That study can either be valid or invalid (represented by  and
and  ). The reported evidence was calculated under the assumption that the study was valid. So:
). The reported evidence was calculated under the assumption that the study was valid. So:
![\[ E = (\text{reported evidence}) = \log_{10}\left(\dfrac{Pr(D | H_1 \& V)}{Pr(D | H_2 \& V)}\right) \]](https://lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-16239f35bd2e7966d6a637bfc5fbd64e_l3.png "Rendered by QuickLaTeX.com")

From the perspective of an observer interpreting a study with trust  , we can calculate the effective evidence,
, we can calculate the effective evidence,  .
.

We define G as the resulting evidence in case the study is invalid.
![\[ G = log\left(\frac{P(D|H_1\&\overline{V})}{P(D|H_2\&\overline{V})}\right) \]](https://lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-bb23a1780942da0bf51f19966a7f842a_l3.png "Rendered by QuickLaTeX.com")

![\[ \Rightarrow \Hat{E} &= \log\left( \dfrac{(1 + 10^{-E})^{-1} 10^T + \dfrac{P(D|H_1\&\overline{V})+P(D|H_2\&\overline{V})}{P(D|H_1\&V)+P(D|H_2\&V)}(1 + 10^{-G})^{-1}}{(1 + 10^{E})^{-1} 10^T + \dfrac{P(D|H_1\&\overline{V})+P(D|H_2\&\overline{V})}{P(D|H_1\&V)+P(D|H_2\&V)}(1 + 10^{G})^{-1}} \right) \]](https://lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-3de4ed02a2eb351448ad5765c6f219dd_l3.png "Rendered by QuickLaTeX.com")
Here we are going to make another simplification: The second assumption is that if a study is invalid, it provides no evidence for or against H1 versus H2. In other words G = 0. This means  =
=  =
=  . Substituting for these values we get:
. Substituting for these values we get:

And to simplify the above formula we define another term: believability. Believability (B) is defined below.
![\[ B = log \left( \dfrac{P(D|H_1\&V)+P(D|H_2\&V)}{P(D|H_{1 \lor 2} \&\overline{V})} \right) \]](https://lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-07e2f64293a67ae1134e31c13655d197_l3.png "Rendered by QuickLaTeX.com")
Substituting B we get the following:

It’s alright if you didn’t closely follow the math up to here. What is important is that we now have a formula for calculating effective evidence  based on reported evidence
based on reported evidence  , trust
, trust  , and believability
, and believability  .
.
![\[ \Hat{E} = E + \log\left( \dfrac{ 10^{(T+B)} + 10^{-E} + 1}{ 10^{(T+B)} + 10^{E} + 1} \right) \]](https://lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-66b47d3bd9b05fd6497a8ba396027b56_l3.png "Rendered by QuickLaTeX.com")
The reported evidence is an objective number we get from the study. Trust is a subjective quantity that the subjects interpreting the study must determine for themselves, independent of the outcome of the study. Believability is a bit more complex. Believability is a number ascribed to a particular outcome or observation, much like evidence is. But in contrast to evidence, believability cannot be determined objectively. This is because of the term  which has to be determined by the interpreter; it is subjective and can vary for different people. I will write more about believability in the next part of this series. (Suffice it to say that a study can be designed to guarantee a believability of B≥0).
which has to be determined by the interpreter; it is subjective and can vary for different people. I will write more about believability in the next part of this series. (Suffice it to say that a study can be designed to guarantee a believability of B≥0).
| meaning | subjective/objective | dependence on study | range | |
| Evidence (E) | amount of evidence provided by the study’s outcome | objectively calculated | depends on outcome | positive (in case the data favors H1) or negative (in case it favors H2) |
| Trust (T) | amount of trust placed in a study prior to seeing the outcome | determined subjectively | independent of outcome | typically a positive number between 1 and 3 |
| Believability (B) | amount of believability ascribed to the outcome of an experiment | determined subjectively, but a lower bound can sometimes be objectively calculated | depends on outcome | negative if the outcome is an indication that the study is likely flawed. The ideal study guarantees that B≥0. |
To gain a better understanding about how the above formula works, I made the following plot.
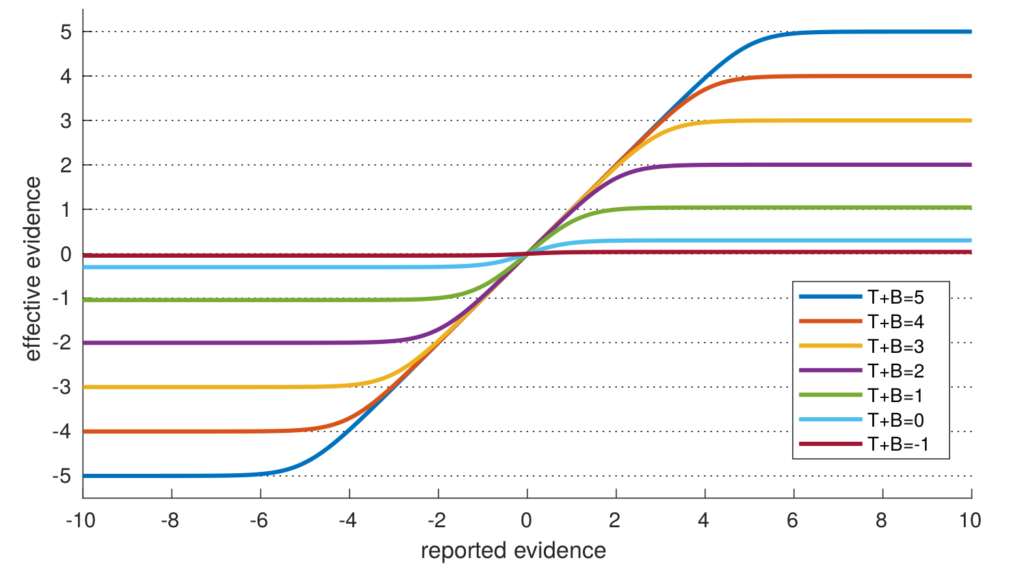
Effective evidence begins to grow linearly with respect to reported evidence. But it plateaus at (T+B). In other words, evidence is effectively limited by how much a study can be trusted plus the believability of the study’s outcome. To first approximation, the magnitude of effective evidence is roughly equal to min(|E|, T+B). This approximation is least accurate when |E| ≈ T+B or when T+B < 1.
This formalizes our intuition that no single study can be used to decisively confirm or deny a hypothesis, no matter how strong the evidence turns out to be in that study. The amount of trust one places in a study limits the amount of evidence that can be acquired from it. For example, if you place a trust of T=1.5 in the typical paper, no single study can convince you by more than 1.5 units of evidence (assuming B=0; more on believability later). You would need to add the effective evidence () from multiple independent studies to establish that there is higher than 1.5 units of evidence for something. This aspect of our framework is nice, because astronomically large or small values are commonplace when working with likelihood ratios. But by accounting for trust, extremely large amounts of reported evidence are not extremely informative.
A meta analysis of multiple studies can be done by calculating the effective evidence for each study and then summing the values. 10 studies that each report 2 units of evidence will almost certainly prevail over one [conflicting] study that reports -20 units of evidence, given that no study can reasonably be trusted with T≥20. If T = 3 and B = 0, then the overall evidence in this case is is 10×2-3 = 9. (Each of the first 10 studies will have an effective evidence of 2 and the single conflicting study will have an effective evidence of -3).
Now, here is a problem that will lead us to the next part. How do we deal with believability? From the perspective of a researcher, we would like to maximize it since it limits the evidence that can be deduced from a study.
If the outcome of an experiment is a continuous value, then all the probabilities in the above formulas can get infinitesimally small. The numerator depends on the person evaluating our study and can be infinitely large for some inconveniently skeptical interpreter. So there is no limit to how negative believability can get! If believability is not dealt with in a study, there is no guarantee that a skeptical interpreter can take away any information from that study. What can be done to guarantee something like this will not happen? I will discuss this in part 3.