In part 1, we defined evidence and showed that evidence across independent studies can be aggregated by addition; if Alice’s results provide 2 units of evidence and Bob’s results provide 3 units of evidence then we have a total of 5 units of evidence. The problem with this is that it doesn’t account for our intuition that single experiments cannot be trusted too much until they are replicated. 10 congruent studies each reporting 2 units of evidence should prevail over one conflicting study showing -20 units of evidence.
Let’s try to model this by assuming that every experiment has a chance of being flawed due to some mistake or systematic error. Each study can have its own probability of failure, in which case the results of that experiment should not be used at all. This is our first assumption: that any result is either completely valid or completely invalid. It is a simplification but a useful one.
We define trust (T) in a particular study as the logarithm of the odds ratio for the being valid versus being invalid. In formal terms:
I am going to introduce a statistical framework for quantifying evidence as a series of blog posts. My hope is that by doing it through this format, people will understand it, build on these ideas, and actually use it as a practical replacement for p-value testing. If you haven’t already seen my post on why standard statistical methods that use p-values are flawed, you can check it out through this link.
My proposal builds on Bayesian hypothesis testing. Bayesian hypothesis testing makes use of the Bayes factor, which is the likelihood ratio of observing some data D for two competing hypotheses H1 and H2. A Bayes factor larger than 1 counts as evidence in favor of hypothesis H1; a smaller than one Bayes factor counts as evidence in favor of H2.
In classical hypothesis testing, we typically set a threshold for the p-value (say, p<0.01) below which a hypothesis can be rejected. But in the Bayesian framework, no such threshold can be defined as hypothesis rejection/confirmation will depend on the prior probabilities. Prior probabilities (i.e., the probabilities assigned prior to seeing data) are subjective. One person may assign equal probabilities for H1 and H2. Another may think H1 is ten times more likely than H2. And neither can be said to be objectively correct. But the Bayesian method leaves this subjective part out of the equation, allowing anyone to multiply the Bayes factor into their own prior probability ratio to obtain a posterior probability ratio. Depending on how likely you think the hypotheses are, you may require more or less evidence in order to reject one in favor of the other.
Let us define ‘evidence‘ as the logarithm of the Bayes factor. The logarithmic scale is much more convenient to work with, as we will quickly see.
Evidence is a quantity that depends on a particular observation or outcome and relates two hypothesis to one another. It can be positive or negative. For example, one can say Alice’s experimental results provide 3 units of evidence in favor of hypothesis H1 against hypothesis H2, or equivalently, -3 units of evidence in favor of hypothesis H2 against hypothesis H1.
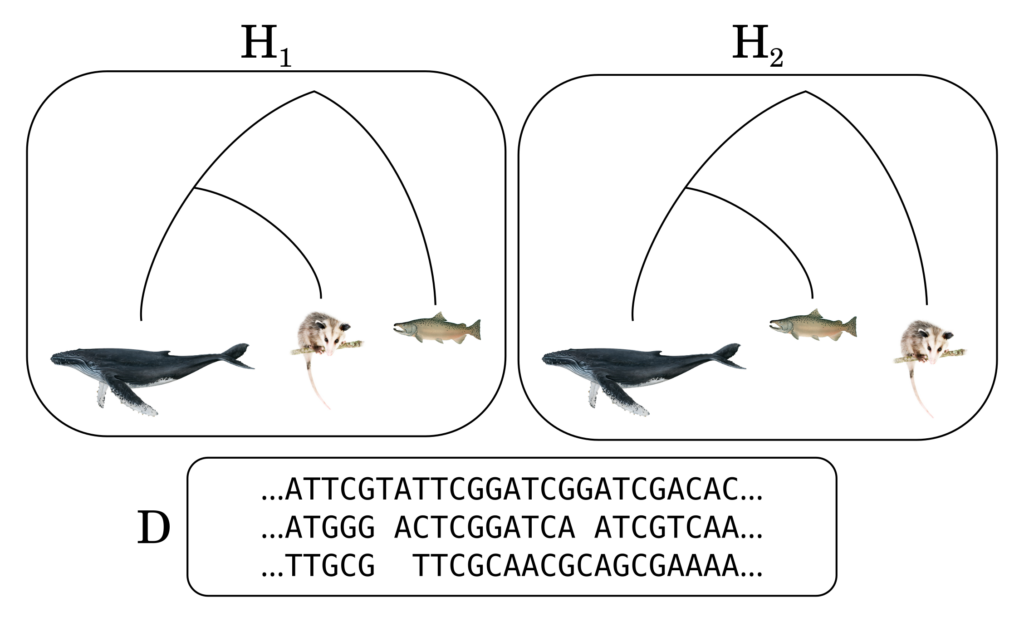
Figure 1: In this example, two hypotheses are being tested against one another. H1 is the hypothesis that the opossum is genetically closer to humpback whales than salmon is. H2 is the hypothesis that salmon is closer to humpback whales than the opossum. The data D that is being used to compare these hypotheses can be some DNA sequencing data, for instance. (The data here isn’t real).
Suppose I tell you that only 1% of people with COVID have a body temperature less than 97°. If you take someone’s temperature and measure less than 97°, what is the probability that they have COVID? If your answer is 1% you have committed the conditional probability fallacy and you have essentially done what researchers do whenever they use p-values. In reality, these inverse probabilities (i.e., probability of having COVID if you have low temperature and probability of low temperature if you have COVID) are not the same.
To put it plain and simple: in practically every situation that people use statistical significance, they commit the conditional probability fallacy.
When I first realized this it hit me like a ton of bricks. P-value testing is everywhere in research; it’s hard to find a paper without it. I knew of many criticisms of using p-values, but this problem was far more serious than anything I had heard of. The issue is not that people misuse or misinterpret p-values. It’s something deeper that strikes at the core of p-value hypothesis testing.
This flaw has been raised in the literature over and over again. But most researchers just don’t seem to know about it. I find it astonishing that a rationally flawed method continues to dominate science, medicine, and other disciplines that pride themselves in championing reason and rationality.

![\[ \dfrac{Pr(H_1 | \text{data})}{Pr(H_2 | \text{data})} = \dfrac{Pr(\text{data} | H_1)}{Pr(\text{data} | H_2)} \times \dfrac{Pr(H_1)}{Pr(H_2)} \]](https://www.lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-df95b7125adc35b4b473b4b8ccab31f5_l3.png "Rendered by QuickLaTeX.com")
![\[ \text{posterior odds ratio} = \text{Bayes factor} \times \text{prior odds ratio} \]](https://www.lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-dafa7311997e2041981f204ffe3f02be_l3.png "Rendered by QuickLaTeX.com")
![\[ E = \text{(evidence for $H_1$ against $H_2$ given $D$)} = \log_{10}(\text{Bayes factor}) = \log_{10}(\dfrac{Pr(D | H_1)}{Pr(D | H_2)}) \]](https://www.lifeiscomputation.com/wp-content/ql-cache/quicklatex.com-8d2a78b686ce528e82a4ec55112d3180_l3.png "Rendered by QuickLaTeX.com")